 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIBISAgent: Reinforcing Pixel-Level Visual Reasoning in MLLMs for Universal Biomedical Object Referring and Segmentation
Jan 06, 2026Recent research on medical MLLMs has gradually shifted its focus from image-level understanding to fine-grained, pixel-level comprehension. Although segmentation serves as the foundation for pixel-level understanding, existing approaches face two major challenges. First, they introduce implicit segmentation tokens and require simultaneous fine-tuning of both the MLLM and external pixel decoders, which increases the risk of catastrophic forgetting and limits generalization to out-of-domain scenarios. Second, most methods rely on single-pass reasoning and lack the capability to iteratively refine segmentation results, leading to suboptimal performance. To overcome these limitations, we propose a novel agentic MLLM, named IBISAgent, that reformulates segmentation as a vision-centric, multi-step decision-making process. IBISAgent enables MLLMs to generate interleaved reasoning and text-based click actions, invoke segmentation tools, and produce high-quality masks without architectural modifications. By iteratively performing multi-step visual reasoning on masked image features, IBISAgent naturally supports mask refinement and promotes the development of pixel-level visual reasoning capabilities. We further design a two-stage training framework consisting of cold-start supervised fine-tuning and agentic reinforcement learning with tailored, fine-grained rewards, enhancing the model's robustness in complex medical referring and reasoning segmentation tasks. Extensive experiments demonstrate that IBISAgent consistently outperforms both closed-source and open-source SOTA methods. All datasets, code, and trained models will be released publicly.
Multi-Agent Intelligence for Multidisciplinary Decision-Making in Gastrointestinal Oncology
Dec 23, 2025Multimodal clinical reasoning in the field of gastrointestinal (GI) oncology necessitates the integrated interpretation of endoscopic imagery, radiological data, and biochemical markers. Despite the evident potential exhibited by Multimodal Large Language Models (MLLMs), they frequently encounter challenges such as context dilution and hallucination when confronted with intricate, heterogeneous medical histories. In order to address these limitations, a hierarchical Multi-Agent Framework is proposed, which emulates the collaborative workflow of a human Multidisciplinary Team (MDT). The system attained a composite expert evaluation score of 4.60/5.00, thereby demonstrating a substantial improvement over the monolithic baseline. It is noteworthy that the agent-based architecture yielded the most substantial enhancements in reasoning logic and medical accuracy. The findings indicate that mimetic, agent-based collaboration provides a scalable, interpretable, and clinically robust paradigm for automated decision support in oncology.
MedBench v4: A Robust and Scalable Benchmark for Evaluating Chinese Medical Language Models, Multimodal Models, and Intelligent Agents
Nov 19, 2025Recent advances in medical large language models (LLMs), multimodal models, and agents demand evaluation frameworks that reflect real clinical workflows and safety constraints. We present MedBench v4, a nationwide, cloud-based benchmarking infrastructure comprising over 700,000 expert-curated tasks spanning 24 primary and 91 secondary specialties, with dedicated tracks for LLMs, multimodal models, and agents. Items undergo multi-stage refinement and multi-round review by clinicians from more than 500 institutions, and open-ended responses are scored by an LLM-as-a-judge calibrated to human ratings. We evaluate 15 frontier models. Base LLMs reach a mean overall score of 54.1/100 (best: Claude Sonnet 4.5, 62.5/100), but safety and ethics remain low (18.4/100). Multimodal models perform worse overall (mean 47.5/100; best: GPT-5, 54.9/100), with solid perception yet weaker cross-modal reasoning. Agents built on the same backbones substantially improve end-to-end performance (mean 79.8/100), with Claude Sonnet 4.5-based agents achieving up to 85.3/100 overall and 88.9/100 on safety tasks. MedBench v4 thus reveals persisting gaps in multimodal reasoning and safety for base models, while showing that governance-aware agentic orchestration can markedly enhance benchmarked clinical readiness without sacrificing capability. By aligning tasks with Chinese clinical guidelines and regulatory priorities, the platform offers a practical reference for hospitals, developers, and policymakers auditing medical AI.
Benchmarking Ethical and Safety Risks of Healthcare LLMs in China-Toward Systemic Governance under Healthy China 2030
May 12, 2025
Large Language Models (LLMs) are poised to transform healthcare under China's Healthy China 2030 initiative, yet they introduce new ethical and patient-safety challenges. We present a novel 12,000-item Q&A benchmark covering 11 ethics and 9 safety dimensions in medical contexts, to quantitatively evaluate these risks. Using this dataset, we assess state-of-the-art Chinese medical LLMs (e.g., Qwen 2.5-32B, DeepSeek), revealing moderate baseline performance (accuracy 42.7% for Qwen 2.5-32B) and significant improvements after fine-tuning on our data (up to 50.8% accuracy). Results show notable gaps in LLM decision-making on ethics and safety scenarios, reflecting insufficient institutional oversight. We then identify systemic governance shortfalls-including the lack of fine-grained ethical audit protocols, slow adaptation by hospital IRBs, and insufficient evaluation tools-that currently hinder safe LLM deployment. Finally, we propose a practical governance framework for healthcare institutions (embedding LLM auditing teams, enacting data ethics guidelines, and implementing safety simulation pipelines) to proactively manage LLM risks. Our study highlights the urgent need for robust LLM governance in Chinese healthcare, aligning AI innovation with patient safety and ethical standards.
Building a Human-Verified Clinical Reasoning Dataset via a Human LLM Hybrid Pipeline for Trustworthy Medical AI
May 11, 2025Despite strong performance in medical question-answering, the clinical adoption of Large Language Models (LLMs) is critically hampered by their opaque 'black-box' reasoning, limiting clinician trust. This challenge is compounded by the predominant reliance of current medical LLMs on corpora from scientific literature or synthetic data, which often lack the granular expert validation and high clinical relevance essential for advancing their specialized medical capabilities. To address these critical gaps, we introduce a highly clinically relevant dataset with 31,247 medical question-answer pairs, each accompanied by expert-validated chain-of-thought (CoT) explanations. This resource, spanning multiple clinical domains, was curated via a scalable human-LLM hybrid pipeline: LLM-generated rationales were iteratively reviewed, scored, and refined by medical experts against a structured rubric, with substandard outputs revised through human effort or guided LLM regeneration until expert consensus. This publicly available dataset provides a vital source for the development of medical LLMs that capable of transparent and verifiable reasoning, thereby advancing safer and more interpretable AI in medicine.
A Regularized Newton Method for Nonconvex Optimization with Global and Local Complexity Guarantees
Feb 07, 2025


We consider the problem of finding an $\epsilon$-stationary point of a nonconvex function with a Lipschitz continuous Hessian and propose a quadratic regularized Newton method incorporating a new class of regularizers constructed from the current and previous gradients. The method leverages a recently developed linear conjugate gradient approach with a negative curvature monitor to solve the regularized Newton equation. Notably, our algorithm is adaptive, requiring no prior knowledge of the Lipschitz constant of the Hessian, and achieves a global complexity of $O(\epsilon^{-\frac{3}{2}}) + \tilde O(1)$ in terms of the second-order oracle calls, and $\tilde O(\epsilon^{-\frac{7}{4}})$ for Hessian-vector products, respectively. Moreover, when the iterates converge to a point where the Hessian is positive definite, the method exhibits quadratic local convergence. Preliminary numerical results illustrate the competitiveness of our algorithm.
Diffusion-Driven Self-Supervised Learning for Shape Reconstruction and Pose Estimation
Mar 19, 2024



Fully-supervised category-level pose estimation aims to determine the 6-DoF poses of unseen instances from known categories, requiring expensive mannual labeling costs. Recently, various self-supervised category-level pose estimation methods have been proposed to reduce the requirement of the annotated datasets. However, most methods rely on synthetic data or 3D CAD model for self-supervised training, and they are typically limited to addressing single-object pose problems without considering multi-objective tasks or shape reconstruction. To overcome these challenges and limitations, we introduce a diffusion-driven self-supervised network for multi-object shape reconstruction and categorical pose estimation, only leveraging the shape priors. Specifically, to capture the SE(3)-equivariant pose features and 3D scale-invariant shape information, we present a Prior-Aware Pyramid 3D Point Transformer in our network. This module adopts a point convolutional layer with radial-kernels for pose-aware learning and a 3D scale-invariant graph convolution layer for object-level shape representation, respectively. Furthermore, we introduce a pretrain-to-refine self-supervised training paradigm to train our network. It enables proposed network to capture the associations between shape priors and observations, addressing the challenge of intra-class shape variations by utilising the diffusion mechanism. Extensive experiments conducted on four public datasets and a self-built dataset demonstrate that our method significantly outperforms state-of-the-art self-supervised category-level baselines and even surpasses some fully-supervised instance-level and category-level methods.
Video Frame Interpolation with Stereo Event and Intensity Camera
Jul 17, 2023



The stereo event-intensity camera setup is widely applied to leverage the advantages of both event cameras with low latency and intensity cameras that capture accurate brightness and texture information. However, such a setup commonly encounters cross-modality parallax that is difficult to be eliminated solely with stereo rectification especially for real-world scenes with complex motions and varying depths, posing artifacts and distortion for existing Event-based Video Frame Interpolation (E-VFI) approaches. To tackle this problem, we propose a novel Stereo Event-based VFI (SE-VFI) network (SEVFI-Net) to generate high-quality intermediate frames and corresponding disparities from misaligned inputs consisting of two consecutive keyframes and event streams emitted between them. Specifically, we propose a Feature Aggregation Module (FAM) to alleviate the parallax and achieve spatial alignment in the feature domain. We then exploit the fused features accomplishing accurate optical flow and disparity estimation, and achieving better interpolated results through flow-based and synthesis-based ways. We also build a stereo visual acquisition system composed of an event camera and an RGB-D camera to collect a new Stereo Event-Intensity Dataset (SEID) containing diverse scenes with complex motions and varying depths. Experiments on public real-world stereo datasets, i.e., DSEC and MVSEC, and our SEID dataset demonstrate that our proposed SEVFI-Net outperforms state-of-the-art methods by a large margin.
A Semantic Segmentation Network for Urban-Scale Building Footprint Extraction Using RGB Satellite Imagery
Apr 02, 2021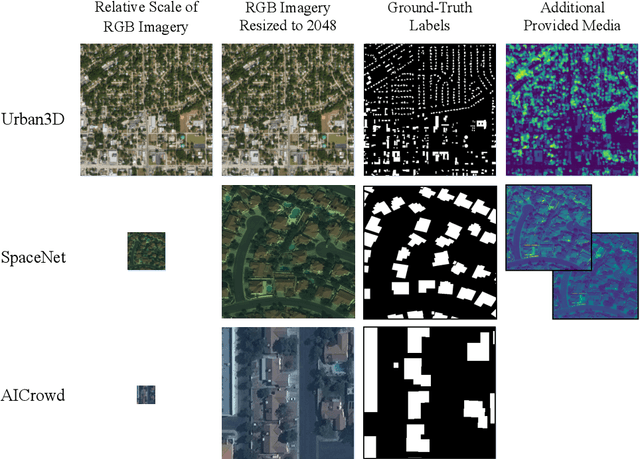
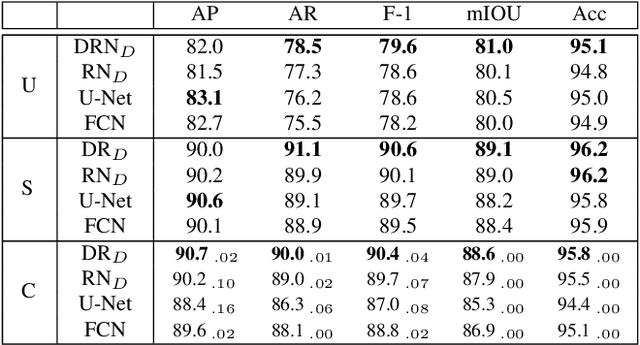
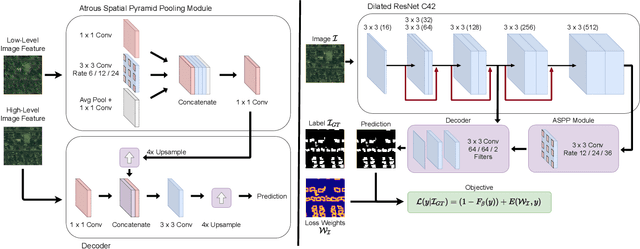
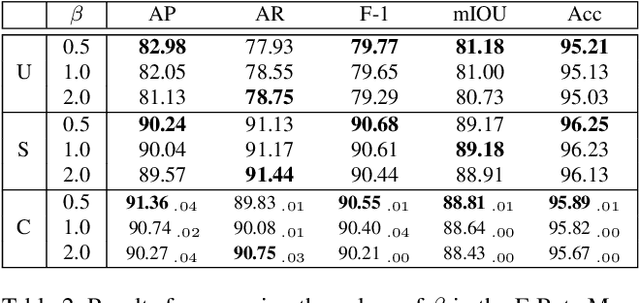
Urban areas consume over two-thirds of the world's energy and account for more than 70 percent of global CO2 emissions. As stated in IPCC's Global Warming of 1.5C report, achieving carbon neutrality by 2050 requires a scalable approach that can be applied in a global context. Conventional methods of collecting data on energy use and emissions of buildings are extremely expensive and require specialized geometry information that not all cities have readily available. High-quality building footprint generation from satellite images can accelerate this predictive process and empower municipal decision-making at scale. However, previous deep learning-based approaches use supplemental data such as point cloud data, building height information, and multi-band imagery - which has limited availability and is difficult to produce. In this paper, we propose a modified DeeplabV3+ module with a Dilated ResNet backbone to generate masks of building footprints from only three-channel RGB satellite imagery. Furthermore, we introduce an F-Beta measure in our objective function to help the model account for skewed class distributions. In addition to an F-Beta objective function, we incorporate an exponentially weighted boundary loss and use a cross-dataset training strategy to further increase the quality of predictions. As a result, we achieve state-of-the-art performance across three standard benchmarks and demonstrate that our RGB-only method is agnostic to the scale, resolution, and urban density of satellite imagery.
Matrix optimization based Euclidean embedding with outliers
Dec 23, 2020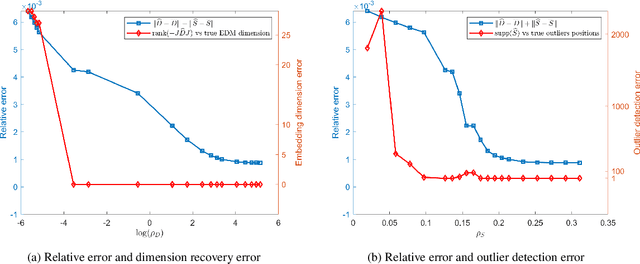
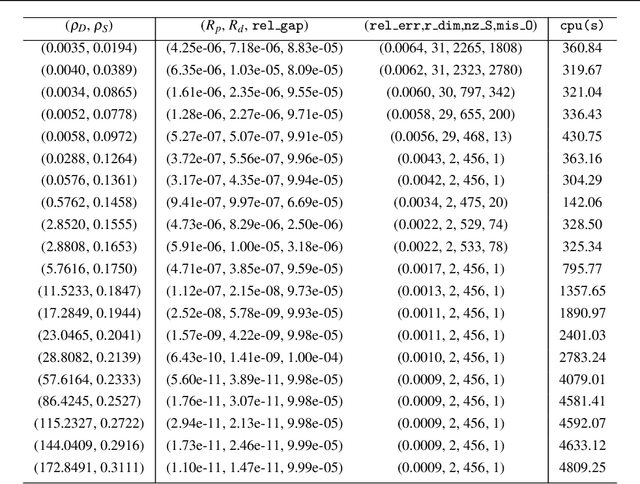
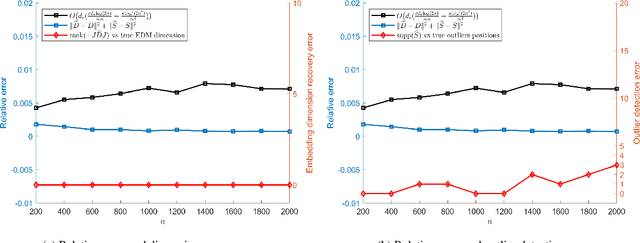
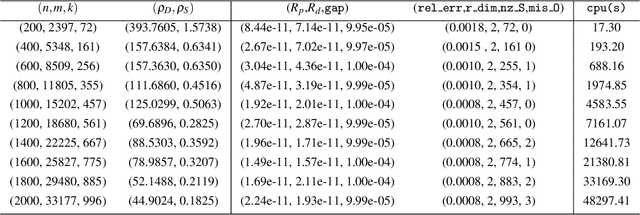
Euclidean embedding from noisy observations containing outlier errors is an important and challenging problem in statistics and machine learning. Many existing methods would struggle with outliers due to a lack of detection ability. In this paper, we propose a matrix optimization based embedding model that can produce reliable embeddings and identify the outliers jointly. We show that the estimators obtained by the proposed method satisfy a non-asymptotic risk bound, implying that the model provides a high accuracy estimator with high probability when the order of the sample size is roughly the degree of freedom up to a logarithmic factor. Moreover, we show that under some mild conditions, the proposed model also can identify the outliers without any prior information with high probability. Finally, numerical experiments demonstrate that the matrix optimization-based model can produce configurations of high quality and successfully identify outliers even for large networks.